Visualization of Convolutional Neural Network's representation of images from Calvino's artworks
- Martin Calvino
- Sep 7, 2019
- 9 min read
Updated: Apr 16, 2020
Synopsis_
Previously a Convolutional Neural Network was used by the author to classify images derived from artworks containing handmade visual elements relative to images derived from artworks created entirely with computer code [1]. However, the visual concepts learned by the network that helped it to correctly classify artworks weren't investigated. In this work the author explored a visualization technique [2] to elucidate the inner workings of Convolutional Neural Networks as means to acquire a higher level of understanding of what may distinguish art created by means of hand gestures as opposed to art created by writing code.
Background_
The representation of visual concepts learned by Convolutional Neural Networks (herein convnets) can be subjected to visualization thanks to a range of techniques developed for interpreting these representations [2]. Three of these techniques include:
> Visualization of intermediate convnets outputs (intermediate activations) -
Allows for the understanding of how successive layers transform their input, and for the obtention of general ideas of the meaning of individual convnets filters
> Visualization of convnets filters -
Allows for a concrete understanding of what visual concepts/patterns individual filters are receptive to
> Visualization of heatmaps for class activation in an image -
Allows for the understanding of which parts/sections of an image were detected as belonging to a given class, and thus enabling the localization of objects in images
In this work, the author focused his attention to the first technique -activation visualization- for which he used the convnet previously trained from scratch on the 'hand_made'-versus-'algorithmic_created'-artworks classification problem previously published [1].
Visualization of intermediate activations_
The feature maps that are output by a convnet layer (either a convolution or pooling layer) given a certain input can be visualized. The output of a layer is called its activation and represents the output of the activation function. Thus, the visualization of intermediate activations in a convnet provides a view into how an input is decomposed into different filters learned by the network. Feature maps are visualized according to three dimensions: width, height, and channel; with each channel encoding relatively independent features. This means that a feature map can be visualized by plotting the content of any given channel as a 2D image. Figure 1 shows the model saved on the artwork classification problem previously published [1] and serves as a remainder of the network architecture used.

Figure 1. Summary of the network architecture previously used to classify artworks containing visual elements created from hand gestures versus artworks created by writing computer code [1]. Code is written in Python and uses Keras as deep learning framework/library.
As input images for visualization the author used two photographs that were correctly classified as containing hand made visual elements relative to algorithmically created artworks [1]; these images were not part of the training and test data sets (Figure 2).

Figure 2a. Image depicting Python code that uses single images as input.




Figure 2b. Displayed are the images used as input to visualize intermediate activations. Left: artwork containing visual elements derived from hand gestures. Right: artwork containing visual elements entirely created by writing computer code.
For the extraction and visualization of feature maps, the Keras class Model was used. This model differs from the Sequential model used in [1] in that it allows the mapping of inputs to multiple outputs (Figure 3a). When an input image from Fig. 2b is fed, this model returns the values of the layer activations in the original model. For instance, the activation for the InputLayer from Fig. 1 for the images shown on Fig.2b are 224 x 224 feature maps with 3 channels. Plotting the 3 channels for both feature maps allowed the author to visualize the representation learned by the InputLayer (Figure 3b).

Figure 3a. Python code to visualize intermediate activations from images shown in Figure 2b.












Figure 3b. Intermediate activations for the 3 channels of the InputLayer (see Fig. 1). Although slight differences in the learned visual representations can already be seen from each channel, most of visual features from the original images are retained after the InputLayer output.
When the output from the second layer was visualized (see 'block1_conv1 (Conv2D)' layer from Fig.1) for the first three channels, distinct visual representations were already learned for each channel, giving the author the first glimpse at what a convnet may different between artworks (Figure 3c). For instance the first channel appears to be a 'texture' detector whereas the second channel appears to be a 'red color' detector.












Figure 3c. Image showing intermediate activations from the 'block1_conv1 (Conv2D)' layer of shape (None, 224, 224, 64) in which the first 3 activations (out of 64 total) for each input image are shown.
The author then plotted a complete visualization of all the activations in the network by extracting and plotting every channel in each of the 19 activation maps (Figure 4), and stacked the result in a single image tensor; with channels stacked side by side [2].

Figure 4a. Python code utilized to plot a complete visualization for all the activations in the network shown on Fig. 1.






Figure 4b. Displayed are images showing intermediate activations for the first 6 layers in the network when an image from hand gesture derived artwork was used as input. Each squared image depicts a channel and its corresponding learned representation. Dark squares depict that the learned representation for that particular channel was not present in the original figure.






Figure 4c. Displayed are images showing intermediate activations for the first 6 layers in the network when an image from written code derived artwork was used as input. Each squared image depicts a channel and its corresponding learned representation. Dark squares depict that the learned representation for that particular channel was not present in the original figure.
As shown in Fig. 4, the visualization of intermediate activations showed that learned representations increasingly became more abstract in deeper layers and carried increasingly less information about the visual content of the original images and more about the relevant content of the class of the images (hand made or computer made). As the artist who created the input images, the visual patterns evidenced for channels in each layer of the network were found to be extremely interesting. They suggested possible avenues for creative exploration of novel visual elements to be created and combined.
Visualization of convnets filters_
This technique allows for the inspection of visual concepts/patterns that any given filter is meant to be receptive to [2]. This would be the equivalent of running the network in reverse [3], which means that instead of inputting an image of an artwork to the network and asking it what it is (hand made or computer made); the network is told what to see and ask it to modify the image in a manner that makes it see the detected item more pronounced. The technicality of this involves gradient ascent in input space [2], which involves the application of gradient descent to the value of the input image of a convnet so as to maximize the response of a given filter, starting from a blank input image or any other image (like in this work). This means that the resulting image used as input will be giving rise to an image that the chosen filter is maximally preceptive/responsive to.
As described in [2], the process involves the building of a 'loss function that maximizes the value of a given filter in a given convolution layer, and then use stochastic gradient descent to adjust the values of the input image so as to maximize this activation value'. The code implementation of this for the activation of filter 1 in the layer block3_conv1 when images shown on Figure 2b were used as input is shown on Figure 5a and the resulting images are shown on Figure 5b, respectively.

Figure 5a. Python code implementation taken from [2] to visualize the activation of single filters and adapted by M.Calvino to input images shown on Figure 2b of this work.




Figure 5b. Activation visualization of filter 1 for the layer block3_conv1 when images from Figure 2b were used as input.
As it can be seen from Figure 5a, the visualization of activations for the same filter gave slightly different results when input image containing hand made visual elements was used relative to an input image derived from an artwork created with computer code. This was also evidenced in a more dramatic manner for the filter 300 of the layer block4_conv3 as shown on Figure 5c.




Figure 5c. Activation visualization of filter 300 for the layer block4_conv3 when images from Figure 2b were used as input.
In order to glance at the range of visual receptiveness among different filters of a network layer, the activation visualization for the first 64 filters of the layer block3_conv1 is shown on Figure 5d when the left image from Figure 2b was used as input.

Figure 5d. Activation visualization of the first 64 filters for the layer block3_conv1 when the left image from Figure 2b was used as input.
Activation visualizations produce very particular aesthetics that could be considered 'artistic' in their own sense. It is unclear to me at this moment how to integrate them into my creative process and artistic output. Take for instance the activation visualization shown on Figure 6, which is quite interesting although not completely aesthetically fulfilling to me. It will require much more experimentation and work from my part as to how activation visualizations could be incorporate into artistic creation.

Figure 6. Activation visualization that could be deemed 'artistic' according to the author's judgement.
Visualization of heatmaps for class activation in an image_
This visualization technique is quite useful for understanding which regions of a given image led a convnet to its final classification decision [2]. Furthermore, it also helps in debugging the decision process of a convnet in those cases were a classification mistake was made. The technique presented here is referred as class activation map (CAM) visualization and consists of creating heatmaps of class activation over input images. In this sense, a class activation heatmap is then a 2D grid of scores associated with a specific output class, computed for every location within an input image, signaling how relevant each location is with respect to the class under consideration. For instance, given an image of an artwork fed into the previously described hand-made vs computer_made convnet [1], CAM visualization allows for the generation of a heatmap for the class 'hand_made', indicating how hand_made-like regions of the image are, and also a heatmap for the class 'computer_made', indicating how computer_made-like regions of the image are. The specifics of the technique is explained in [2] as follow; and consists of taking the output feature map of a convolution layer, given an input image, and weighing every channel in that feature map by the gradient of the class with respect to the channel. Conceptually, it would be the equivalent of weighting a spatial map of 'how intensely the input image activates different channels' by 'how important each channel is with regard to the class', giving in return a spatial map of 'how intensely the input image activates the class'. The code implementation according to [2] and modified by the author for this work is shown on Figure 7 and the resulting visual output is shown on Figure 8.

Figure 7. Python code for implementation of Class Activation Map. Code was taken from [2] and modified accordingly by the author.























Figure 8a. Images displaying class activation maps for hand_made related artworks.






















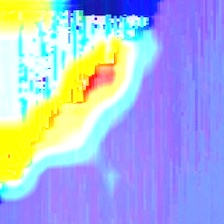
Figure 8b. Images displaying class activation maps for computer_made related artworks.
From the three visualizations presented here, the author considers class activation maps the most interesting and useful in helping him to understand which regions of any given image derived from his artworks were considered more relevant by the trained convolutional neural network in classifying the image as hand_made or computer_made. Thus, CAMs have the potential to help in identifying visual elements that distinguish traditional art making relative to computer and algorithmic art. From Figure 8 it can be seen superposition of lines, points and irregular hand strokes were activated in hand_made artworks. This was not the case for computer_made artworks in which the activated regions were hard edges and on the borders of the image. The question remains as to how best use this information and its incorporation into the author's creative process. One possible outcome from this work that can help in art making is the use of variations of heatmap drawing onto the original painting by altering the values of the 'heatmap intensity factor' from the cv2 module shown on the code displayed on Figure 7. A second approach in conjunction with the alteration of the 'heatmap intensity factor' is to selectively play with the total number of filters (less that 512 that is the maximum number of filters for the block5_pool (MaxPooling 2D) layer) to produce the feature map (Figure 7). Less filters considered will result on heat maps that are more promiscuous and thus recognizing many more regions of the image as important for classification results. To demonstrate the visual outcomes of altering the 'heatmap intensity factor', the author presents five images derived from Figure 8b that could be considered 'artistic' not only because of their aesthetic bu also because they resulted from the hybrid process of an original artwork created with computer code that was altered at specific regions by a learning algorithm that could distinguish those regions as relevant in differentiating algorithmic art relative to hand_made art (Figure 9).










Figure 9. Artworks created by modifying the 'heatmap intensity factor' from the cv2 module at those regions of the image identified by applying 'class activation maps' on algorithmic-derived-artworks shown on Figure 8b.
Without any doubt, the two approaches for art making just explained deserve further investigation into their aesthetic potential for producing artwork deemed interesting by the author. What it's appealing from this approach is that it is not totally automated and thus required the network to learn visual differences from artworks made by the author in order to later manually modify a component of the same code to produce further visual outputs. This means that the approach is truly hybrid in nature and the visual outcome of this work had not been foreseen by the author in any means. This pinpoint to the fact that images shown on Figure 9 are totally experimental in nature and with a visual aesthetics considered novel for the author himself.
References_
[2] Francois Chollet (2018). Deep learning with Python. Published by Manning Publications Co. (Shelter Island, New York)
[3] Douwe Osinga (2018). Deep learning cookbook. Published by O'Reilly Media Inc. (Sebastopol, California)



Comments