Exploratory Data Analysis in R
- Martin Calvino

- Feb 14, 2022
- 29 min read
The utilization of visualization and transformation techniques to explore data in a systematic manner is known as Exploratory Data Analysis (herein EDA). This approach is iterative in nature as you pose questions that guide your research, focusing on particular aspects of your dataset that help you determine which tools to use, gaining insights on your data that in turns lead you to generate new questions. EDA is a creative process in which revealing questions often emerge as result of having asked many trivial questions first. This is so because you don't know a priori what insights are contained in your dataset.
Although there is no formal approach to EDA, the consensus is to start by asking:
1 - What is the variation occurring within the variables of my dataset?
2 - Is there evidence of covariation between variables of my dataset?
Variation occurs when the values of a variable change from measurement to measurement. Because each variable displays its own pattern of variation, relevant information can be revealed by visualizing the distribution of a variable's values. Covariation in turns describes the tendency for the values of two or more variables to vary together in a related way; and thus it explains the behavior among variables.
In this work I use R to explore data containing home mortgage applications in the state of New Jersey for the years 2018, 2019 and 2020, respectively. I obtained these three datasets from the Consumer Financial Protection Bureau's website. They are associated with the Home Mortgage Disclosure Act (HMDA) that requires financial institutions to disclose loan-level information about mortgages.
I am interested in examining the covariation between the ethnicity (latino vs non-latino) of the applicant with the rest of the variables present in the dataset.
OVERAL DESCRIPTION OF HMDA DATA
When the three datasets are merged, the combined data contains 1,117,251 home mortgage applications (observations) across 99 variables, with most applications observed for the year 2020 (Figure 1A). The great majority of applications were concerned with mortgages related to principal residencies (Figure 1B); whereas the purposes of the loan applications were directed towards home purchase and refinancing (Figure 1C).
library(tidyverse)
# mortgage applications for the year 2018 as 'may18'
may18 <- read.csv(file.choose()) #load dataset
str(may18) #data frame containing 295,286 observations and 99 variables
# mortgage applications for the year 2019 as 'may19'
may19 <- read.csv(file.choose()) #load dataset
str(may19) #335,661 observations and 99 variables
# mortgage applications for the year 2020 as 'may20'
may20 <- read.csv(file.choose()) #load dataset
str(may20) #486,304 observations and 99 variables
# merge datasets
comb.data18_19 <- merge(may18, may19, all=TRUE)
comb.data18_19_20 <- merge(comb.data18_19, may20, all=TRUE)
str(comb.data18_19_20) # 1,117,251 observations and 99 variables
View(comb.data18_19_20) # view dataset on RStudio code editor window
# visualize number of home mortgage applications per year
ggplot(data = comb.data18_19_20) +
geom_bar(mapping = aes(x = activity_year)) +
scale_y_continuous(breaks=c(100000, 200000, 300000, 400000, 500000),
labels=c("100,000", "200,000", "300,000", "400,000", "500,000")) +
labs(title="Home Mortgage Applications per Year", x="", y="Number of Applications")
# visualize occupancy type
ggplot(data=comb.data18_19_20) +
geom_bar(mapping=aes(x=occupancy_type)) +
scale_x_continuous(breaks=c(1:3), labels=c("Principal Residence", "Second Residency", "Investment Property")) +
theme(axis.text.x = element_text(angle = 90, hjust=1, vjust=0.5, size = rel(1.0))) +
labs(title="Type of Mortgage Application >> Period: 2018-2019-2020", x="", y="Number of Applications")
# visualize purpose of loan
ggplot(data=comb.data18_19_20) +
geom_bar(mapping=aes(x=loan_purpose)) +
scale_x_discrete(labels=c("Home Purchase", "Home Improvement", "Refinancing", "Cash-out Refinancing", "Other Purpose", "Not Applicable")) +
scale_y_continuous(breaks=c(100000, 200000, 300000, 400000),
labels=c("100,000", "200,000", "300,000", "400,000")) +
theme(axis.text.x = element_text(angle = 90, hjust=1, vjust=0.5, size = rel(1.0))) +
labs(title="Purpose of Loan Application >> Period: 2018-2019-2020", x="Loan Purpose", y="Number of Applications")






Figure 1. Overall description of HMDA dataset for the years 2018-2019-2020 combined. Figure 1A (left) depicts the number of home mortgage applications per year (2018: 295,286 applications; 2019: 335,661 applications; and 2020: 486,304 applications). Figure 1B (middle) depicts the number of home mortgage applications per type (principal residency, second residency, and investment property). Figure 1C (right) depicts the number of home mortgage applications according to loan purpose. Home purchase and refinancing being the two most common purposes.
The HMDA dataset contains home mortgage applications scored across 99 variables including: financial institution, ethnicity, race, sex, income, loan amount and property value to name a few. The variables with values and definitions are clearly explained in the following weblink:
In RStudio, we can see the entire data set using the View() function (Figure 2), which displays the content of the dataset on the code editor panel.
View(comb.data18_19_20) # view dataset on RStudio code editor window
Figure 2. Overview of the combined HMDA dataset for the years 2018, 2019 and 2020 as shown in RStudio with the View() function. The first 17 variables (columns) are shown from 99 variables in total.
Another interesting aspect of the HMDA dataset is the inclusion of all financial institutions in New Jersey that received and processed home mortgage applications (the variable / column named lei on Figure 2). There were 1,061 financial institutions in total; from which the top 50 (in terms of number of application processed) are shown on Figure 3.
# lei/banks
ggplot(data=comb.data18_19_20) +
geom_bar(mapping=aes(x=lei)) +
coord_cartesian(ylim=c(0,100000)) +
scale_y_continuous(breaks=c(10000, 20000, 30000, 40000, 50000, 60000, 70000, 80000, 90000, 100000),
labels=c("10,000", "20,000", "30,000", "40,000", "50,000", "60,000", "70,000", "80,000", "90,000", "100,000")) +
theme(axis.text.x = element_text(angle = 90, hjust=1, vjust=0.5, size = rel(0.5))) +
xlab("Financial Institutions in New Jersey") +
ylab("Number of Home Mortgage Applications")
# inspect financial institutions (lei) in terms of total number of
home mortgage applications received/processed
banks <- factor(comb.data18_19_20$lei)
length(levels(banks)) #1,061 lending institutions (banks)
summary(banks)
# plot top 50 lei(s) in terms of amount of loan applications received
top.50.lei <- c(
"KB1H1DSPRFMYMCUFXT09",
"B4TYDEB6GKMZO031MB27",
"549300FGXN1K3HLB1R50",
"7H6GLXDRUGQFU57RNE97",
"03D0JEWFDFUS0SEEKG89",
"AD6GFRVSDT01YPT1CS68",
"549300LYRWPSYPK6S325",
"549300HW662MN1WU8550",
"549300AG64NHILB7ZP05",
"549300JZD4L02YZI3Z50",
"TR24TWEY5RVRQV65HD49",
"549300J7XKT2BI5WX213",
"549300FNXYY540N23N64",
"549300VZVN841I2ILS84",
"DRMSV1Q0EKMEXLAU1P80",
"549300U3721PJGQZYY68",
"549300F8C5JA44WNMI75",
"549300BCHY7VFHESOE22",
"549300BRJZYHYKT4BJ84",
"5493001WHVQBGRSWEU75",
"254900F9ZTVTX763V835",
"549300MXJA09WZJ0DV55",
"KI0VI4JRMCIJ329YTN75",
"549300LBCBNR1OT00651",
"X05BVSK68TQ7YTOSNR22",
"549300EFCZM6KD6B8K69",
"5493002VB77GOYB9O402",
"549300NOCASXPA34X033",
"2549009V3JISNNLCD785",
"RVDPPPGHCGZ40J4VQ731",
"549300VORTI31GZTJL53",
"549300D4ZYLSQ5LMTV35",
"5493005LKFCLR81TSN28",
"E57ODZWZ7FF32TWEFA76",
"5493002N5168AC238149",
"WWB2V0FCW3A0EE3ZJN75",
"54930034MNPILHP25H80",
"549300YIQ7S7Z8PIHE53",
"549300JNTZTF40KCOF79",
"6BYL5QZYBDK8S7L73M02",
"5493003GQDUH26DNNH17",
"54930063XGNMIXS57091",
"5493004UNRG4PWDF2K60",
"549300LDVDAIKBVCY905",
"5493008NWHQT1R22C024",
"549300ZJ3ZL66QGSGO48",
"549300R9S3MVDV4MGF56",
"549300XY701IELCE5Q08",
"54930001NSTOD85LT125",
"549300SUCQ1358EGVE89"
)
top.50.lei.labels <- c(
"Wells_Fargo",
"Bank_of_America",
"Rocket_Mortgage",
"JPMorgan_Chase_Bank",
"TD_Bank",
"PNC_Bank",
"Freedom_Mortgage_Corporation",
"United Wholesale_Mortgage",
"Loandepot.com",
"NJ_Lenders_Corp",
"Santander_Bank",
"Caliber_Home_Loands",
"Newrez",
"Crosscountry_Mortgage",
"Citizens_Bank",
"Guaranteed_Rate",
"American_Neighborhood_Mortgage",
"Greentree_Mortgage_Company",
"Home_Point_Financial_Corp",
"Homebridge_Financial_Services",
"Advisors_Mortgage_Group",
"Finance_of_America_Mortgage",
"Valley_National_Bank",
"Nationstar_Mortgage_LLC",
"Discover_Bank",
"Mortgage_Access_Corp",
"Investors_Bank",
"Lakeview_Loan_Servicing_LLC",
"Family_First_Funding_LLC",
"Pennymac_Loan_Services_LLC",
"Cardinal_Financial_Company",
"Absolute_Homemortgage_Corp",
"Columbia_Bank",
"Citibank_National_Association",
"OceanFirst_Bank_National_Association",
"Manufacturers_and_Traders_Trust_Company",
"Gateway_First_Bank",
"Amerisave_Mortgage_Corporation",
"Republic_Bank",
"US_Bank_National_Association",
"Navy_Federal_Credit_Union",
"Police_&_Fire",
"Affinity",
"Trident_Mortgage_Company_LP",
"American_Financial_Network_Inc",
"Lakeland_Bank",
"Carrington_Mortgage_Services_LLC",
"Better_Mortgage_Corporation",
"Guaranteed_Rate_Affinity_LLC",
"New_Day_Financial_LLC"
)
# visualize top 50 lei(s)
ggplot(data=comb.data18_19_20) +
geom_bar(mapping=aes(x=lei)) +
coord_cartesian(ylim=c(0,100000)) +
scale_y_continuous(breaks=c(10000, 20000, 30000, 40000, 50000, 60000, 70000, 80000, 90000, 100000),
labels=c("10,000", "20,000", "30,000", "40,000", "50,000", "60,000", "70,000", "80,000", "90,000", "100,000")) +
scale_x_discrete(breaks=top.50.lei, labels=top.50.lei.labels) +
theme(axis.text.x = element_text(angle = 90, hjust=1, vjust=0.5, size = rel(0.75))) +
labs(title="Mortgage Applications per Lending Institution >> Years: 2018-2019-2020", x="Top 50 Lending Institutions in New Jersey", y="Number of Home Mortgage Applications")

Figure 3. Financial Institutions that processed home mortgage applications in New Jersey during the 3 year period of 2018-2019-2020. Top 50 institutions in terms of processed applications are highlighted. Wells Fargo Bank topped the list with 94,799 applications followed by Bank of America with 54,863 applications, respectively.
Although the raw dataset obtained from HMDA is super useful for high level inspection (as I have previously shown), data management approaches are necessary in order to reduce the size of the dataset and to make it more amenable to analysis.
PREPARATION OF HMDA DATASET PRIOR TO EDA
Before embarking on EDA, the raw dataset needs to be 'shaped' or 'prepared' into a form that facilitates its computational processing. For the specific purpose of this work the 'preparation' involves the creation of a new dataset characterized by:
a - selected variables of interest only
b - renamed selected variables with more appropriate (and short) designations & recoded variables when needed
c - removal of observations (applications) containing missing values
d - removal of outliers
From the original 99 variables contained on the raw dataset, I was interested in retaining 15 of them. These variables related to:
Year
Financial Institution
NJ County Code
Ethnicity
Race
Sex
Action Taken (by the Financial Institution on the home mortgage application)
Loan Purpose
Loan Amount
Interest Rate (for the covered home loan or application)
Property Value
Occupancy Type
Income
Debt to Income Ratio
Denial Reason (the reason behind denial of home mortgage application)
# fifthteen (15) variables dataframe as 'fiva'
yr <- comb.data18_19_20$activity_year
fi <- comb.data18_19_20$lei
cc <- comb.data18_19_20$county_code
et <- comb.data18_19_20$derived_ethnicity
ra <- comb.data18_19_20$derived_race
se <- comb.data18_19_20$derived_sex
at <- comb.data18_19_20$action_taken
lp <- comb.data18_19_20$loan_purpose
la <- comb.data18_19_20$loan_amount
ir <- as.numeric(comb.data18_19_20$interest_rate) # variable was coded as character in HMDA raw dataset
pv <- as.numeric(comb.data18_19_20$property_value) # variable was coded as character in HMDA raw dataset
ot <- comb.data18_19_20$occupancy_type
inc <- (comb.data18_19_20$income)*1000
dinra <- comb.data18_19_20$debt_to_income_ratio
dr <- comb.data18_19_20$denial_reason.1
# create new dataframe named fiva with variables of interest
fiva <- data.frame(yr, fi, cc, et, ra, se, at, lp, la, ir, pv, ot, inc, dinra, dr)
str(fiva)
summary(fiva)
As shown above, I created a new data frame containing the selected 15 variables from the original HMDA dataset. For one of the variables, that is 'dinra' or 'debt-to-income-ratio', it was necessary to implement recoding. According to Robert I. Kabacoff on his book 'R In Action', recoding is the creation of new values for a variable depending on the existing values of the same and/or other variables.
# recode dinra variable for fiva
fiva$dinra[fiva$dinra == "<20%"] <- "up_to_19%"
fiva$dinra[fiva$dinra == "20%-<30%"] <- "20_to_29%"
fiva$dinra[fiva$dinra == "30%-<36%"] <- "30_to_35%"
fiva$dinra[fiva$dinra == "36"] <- "36%"
fiva$dinra[fiva$dinra == "37"] <- "37%"
fiva$dinra[fiva$dinra == "38"] <- "38%"
fiva$dinra[fiva$dinra == "39"] <- "39%"
fiva$dinra[fiva$dinra == "40"] <- "40%"
fiva$dinra[fiva$dinra == "41"] <- "41%"
fiva$dinra[fiva$dinra == "42"] <- "42%"
fiva$dinra[fiva$dinra == "43"] <- "43%"
fiva$dinra[fiva$dinra == "44"] <- "44%"
fiva$dinra[fiva$dinra == "45"] <- "45%"
fiva$dinra[fiva$dinra == "46"] <- "46%"
fiva$dinra[fiva$dinra == "47"] <- "47%"
fiva$dinra[fiva$dinra == "48"] <- "48%"
fiva$dinra[fiva$dinra == "49"] <- "49%"
fiva$dinra[fiva$dinra == "50%-60%"] <- "50_to_60%"
fiva$dinra[fiva$dinra == ">60%"] <- "61%_and_above"
head(fiva$dinra, n=50)
Missing values (NAs) were visualized in order to have a better understanding. More than 35% of observations had missing values in the variable interest_rate (ir) (Figure 4). This is normal since denied home mortgage applications don't have an associated interest_rate value. More importantly, if observations containing missing values associated with this variable are removed from the data frame, all home mortgage applications that were denied by the financial institutions would also be removed, seriously affecting the analysis of the data. Missing values co-occurred for the variables income (inc) and debt_to_income_ratio (dinra) as they are related to each other.
# visualize missing values (NAs)
library(VIM)
aggr(fiva, prop=TRUE, numbers=FALSE)

Figure 4. Visualization of missing values with the aggr() function from the VIM package. Proportion of missing values for each variable in the data frame are shown on the left panel; whereas the proportion of co-occuring missing values across variables are shown on the right panel.
After inspection of the values and their distribution for numeric variables (see console output above from running summary(fiva) ), it is evident that outliers needed to be identified and removed (Figure 5). Also, observations containing negative values for the income variable needed to be removed as well for easier interpretation of results. After the completion of these steps, I was left with a dataset of 966,353 home mortgage applications.
# remove outliers one variable at a time
la.outliers <- boxplot(fiva[, 9])$out
fiva.outlier1 <- fiva[-which(fiva[, 9] %in% la.outliers), ]
ir.outliers <- boxplot(fiva.outlier1[, 10])$out
fiva.outlier2 <- fiva.outlier1[-which(fiva.outlier1[, 10] %in% ir.outliers), ]
pv.outliers <- boxplot(fiva.outlier2[, 11])$out
fiva.outlier3 <- fiva.outlier2[-which(fiva.outlier2[, 11] %in% pv.outliers), ]
inc.outliers <- boxplot(fiva.outlier3[, 13])$out
fiva.outlier4 <- fiva.outlier3[-which(fiva.outlier3[, 13] %in% inc.outliers), ]
boxplot(fiva.outlier4[, c(9, 10, 11, 13)])
summary(fiva.outlier4)
# remove observations with negative values for the income variable
fiva.outlier4 <- fiva.outlier4[fiva.outlier4$inc > 0, ]
summary(fiva.outlier4)
boxplot(fiva.outlier4[, c(9, 10, 11, 13)])
# fiva lean as 'fivaL'
fivaL <- fiva.outlier4
str(fivaL) # 966,353 observations/applications




Figure 5. Boxplot visualizing the distribution of values for numeric variables (la: loan_amount / ir: interest_rate / pv: property_value / inc: income) with outliers (left plot) and after their removal (right plot).

As shown above, the statistics for numeric variables from the final data frame named fivaL are summarized and described. I learned that the median for:
loan_amount was $235,000,
interest_rate was 3.75%,
property_value was $365,000,
income was $103,000;
These metrics served as benchmark to which EDA based on ethnicity (latino vs non-latino) will be compared to.
DEVELOPING AN UNDERSTANDING OF HMDA DATA USING EDA
The visualization of the distribution of values within a variable will depend if the variable is categorical or continuous. I first started EDA by taking a look into the categorical variables of my data frame (Figure 6).
# VISUALIZE DISTRIBUTION OF VALUES WITHIN CATEGORICAL VARIABLES
# visualize number of home mortgage applications per year
ggplot(data = fivaL) +
geom_bar(mapping = aes(x = yr)) +
scale_y_continuous(breaks=c(100000, 200000, 300000, 400000, 500000),
labels=c("100,000", "200,000", "300,000", "400,000", "500,000")) +
labs(title="Home Mortgage Applications per Year", x="", y="Number of Applications")
# inspect financial institutions (lei) in terms of total number of home mortgage applications received/processed
fin.inst <- factor(fivaL$fi)
length(levels(fin.inst)) # 993 financial institutions
summary(fin.inst)
fi.ID <- c(
"KB1H1DSPRFMYMCUFXT09",
"549300FGXN1K3HLB1R50",
"B4TYDEB6GKMZO031MB27",
"7H6GLXDRUGQFU57RNE97",
"AD6GFRVSDT01YPT1CS68",
"03D0JEWFDFUS0SEEKG89",
"549300HW662MN1WU8550",
"549300AG64NHILB7ZP05",
"TR24TWEY5RVRQV65HD49",
"549300J7XKT2BI5WX213",
"549300FNXYY540N23N64",
"549300VZVN841I2ILS84",
"549300F8C5JA44WNMI75",
"549300LYRWPSYPK6S325",
"549300U3721PJGQZYY68",
"DRMSV1Q0EKMEXLAU1P80",
"549300BCHY7VFHESOE22",
"549300BRJZYHYKT4BJ84",
"254900F9ZTVTX763V835",
"549300MXJA09WZJ0DV55",
"5493001WHVQBGRSWEU75",
"X05BVSK68TQ7YTOSNR22",
"549300EFCZM6KD6B8K69",
"KI0VI4JRMCIJ329YTN75",
"549300LBCBNR1OT00651",
"2549009V3JISNNLCD785",
"549300D4ZYLSQ5LMTV35",
"5493002VB77GOYB9O402",
"549300VORTI31GZTJL53",
"54930034MNPILHP25H80",
"549300YIQ7S7Z8PIHE53",
"5493005LKFCLR81TSN28",
"549300JZD4L02YZI3Z50",
"549300JNTZTF40KCOF79",
"5493002N5168AC238149",
"54930063XGNMIXS57091",
"549300LDVDAIKBVCY905",
"RVDPPPGHCGZ40J4VQ731",
"5493003GQDUH26DNNH17",
"5493004UNRG4PWDF2K60",
"WWB2V0FCW3A0EE3ZJN75",
"6BYL5QZYBDK8S7L73M02",
"5493008NWHQT1R22C024",
"549300RYWXR8TL5LIK35",
"549300DD4R4SYK5RAQ92",
"549300ZJ3ZL66QGSGO48",
"54930001NSTOD85LT125",
"E57ODZWZ7FF32TWEFA76",
"549300XY701IELCE5Q08",
"254900ZFWS2106HWPH46"
)
fi.num.applications <- c(
77738,
46238,
44583,
34714,
32066,
31424,
21812,
17662,
15922,
14813,
14272,
12937,
11356,
11088,
11003,
10837,
10323,
9350,
9254,
9057,
8506,
8505,
7965,
7929,
6949,
6892,
6801,
6778,
6627,
6431,
6221,
6070,
6010,
5667,
5601,
5566,
5472,
5438,
5374,
5256,
5215,
4993,
4713,
4560,
4502,
4381,
4311,
4224,
4192,
4169
)
fi.name <- c(
"Wells_Fargo_Bank",
"Rocket_Mortgage_LLC",
"Bank_of_America",
"JPMorgan_Chase_Bank",
"PNC_Bank",
"TD_Bank",
"United_Wholesale_Mortgage_LLC",
"Loandepot.com_LLC",
"Santander_Bank",
"Caliber_Home_Loans_Inc.",
"Newrez_LLC",
"Crosscountry_Mortgage_LLC",
"American_Neighborhood_Mortgage_Acceptance_Company_LLC",
"Freedom_Mortgage_Corporation",
"Guaranteed_Rate_Inc.",
"Citizens_Bank",
"Greentree_Mortgage_Company_LP",
"Homepoint_Financial_Corporation",
"Advisors_Mortgage_Group_LLC",
"Finance_of_America_Mortgage_LLC",
"Homebridge_Financial_Services_Inc.",
"Discover_Bank",
"Mortgage_Access_Corpporation",
"Valley_National_Bank",
"Nationstar_Mortgage_LLC",
"Family_First_Funding_LLC",
"Absolute_Home_Mortgage_Corporation",
"Investors_Bank",
"Cardinal_Financial_Company_LP",
"Gateway_First_Bank",
"Amerisave_Mortgage_Corporation",
"Columbia_Bank",
"NJ_Lenders_Corporation",
"Republic_Bank",
"Ocean_First_Bank",
"Police_&_Fire",
"Trident_Mortgage_Company_LP",
"Pennymac_Loan_Services_LLC",
"Navy_Federal_Credit_Union",
"Affinity",
"Manufacturers_and_Traders_Trust_Company",
"US_National_Bank_Association",
"American_Financial_Network_Inc.",
"Allied_Mortgage_Group_Inc.",
"Movement_Mortgage_LLC",
"Lakeland_Bank",
"Guaranteed_Rate_Affinity_LLC",
"Citibank_National_Association",
"Better_Mortgage_Corporation",
"Paramount_Residential_Mortgage_Group_Inc."
)
# visualize all 993 financial institutions but highlight only the top 50
ggplot(data=fivaL) +
geom_bar(mapping=aes(x=fi)) +
coord_cartesian(ylim=c(0,100000)) +
scale_y_continuous(breaks=c(10000, 20000, 30000, 40000, 50000, 60000, 70000, 80000, 90000, 100000),
labels=c("10,000", "20,000", "30,000", "40,000", "50,000", "60,000", "70,000", "80,000", "90,000", "100,000")) +
scale_x_discrete(breaks=fi.ID, labels=fi.name) +
theme(axis.text.x = element_text(angle = 90, hjust=1, vjust=0.5, size = rel(0.75))) +
labs(title="Mortgage Applications per Financial Institution >> Years: 2018-2019-2020", x="Top 50 Financial Institutions in New Jersey Highlighted", y="Number of Home Mortgage Applications")
# create a new data frame with top 50 financial institutions
(data.top50.fi <- filter(fivaL, fi %in% fi.ID))
str(data.top50.fi) # 621,767 observations
summary(data.top50.fi)
# visualize top 50 financial institutions only
ggplot(data=data.top50.fi) +
geom_bar(mapping=aes(x=fi)) +
coord_cartesian(ylim=c(0,80000)) +
scale_y_continuous(breaks=c(10000, 20000, 30000, 40000, 50000, 60000, 70000, 80000),
labels=c("10,000", "20,000", "30,000", "40,000", "50,000", "60,000", "70,000", "80,000")) +
scale_x_discrete(breaks=fi.ID, labels=fi.name) +
theme(axis.text.x = element_text(angle = 90, hjust=1, vjust=0.5, size = rel(0.75))) +
labs(title="Top 50 Financial Institutions in NJ >> Years: 2018-2019-2020", x="", y="Number of Home Mortgage Applications")
# visualize county codes
county.codes <- c(34001, 34003, 34005, 34007, 34009, 34011, 34013, 34015, 34017, 34019, 34021, 34023, 34025, 34027, 34029, 34,031, 34033, 34035, 34037, 34039, 34041)
county.codes.names <- c("Atlantic", "Bergen", "Burlington", "Camden", "Cape_May", "Cumberland", "Essex", "Gloucester", "Hudson", "Hunterdon", "Mercer", "Middlesex", "Monmouth", "Morris", "Passaic", "Ocean", "Salem", "Somerset", "Sussex", "Union", "Warren")
fivaL$cc[fivaL$cc == 34001] <- "Atlantic"
fivaL$cc[fivaL$cc == 34003] <- "Bergen"
fivaL$cc[fivaL$cc == 34005] <- "Burlington"
fivaL$cc[fivaL$cc == 34007] <- "Camden"
fivaL$cc[fivaL$cc == 34009] <- "Cape_May"
fivaL$cc[fivaL$cc == 34011] <- "Cumberland"
fivaL$cc[fivaL$cc == 34013] <- "Essex"
fivaL$cc[fivaL$cc == 34015] <- "Gloucester"
fivaL$cc[fivaL$cc == 34017] <- "Hudson"
fivaL$cc[fivaL$cc == 34019] <- "Hunterdon"
fivaL$cc[fivaL$cc == 34021] <- "Mercer"
fivaL$cc[fivaL$cc == 34023] <- "Middlesex"
fivaL$cc[fivaL$cc == 34025] <- "Monmouth"
fivaL$cc[fivaL$cc == 34027] <- "Morris"
fivaL$cc[fivaL$cc == 34029] <- "Ocean"
fivaL$cc[fivaL$cc == 34031] <- "Passaic"
fivaL$cc[fivaL$cc == 34033] <- "Salem"
fivaL$cc[fivaL$cc == 34035] <- "Somerset"
fivaL$cc[fivaL$cc == 34037] <- "Sussex"
fivaL$cc[fivaL$cc == 34039] <- "Union"
fivaL$cc[fivaL$cc == 34041] <- "Warren"
View(fivaL)
fivaL$cc <- as.character(fivaL$cc)
counties<- factor(fivaL$cc)
length(levels(counties)) # 132 levels
summary(counties)
ggplot(data=fivaL) +
stat_count(mapping=aes(x=cc)) +
coord_cartesian(ylim=c(0,90000)) +
scale_y_continuous(breaks=c(10000, 20000, 30000, 40000, 50000, 60000, 70000, 80000, 90000),
labels=c("10,000", "20,000", "30,000", "40,000", "50,000", "60,000", "70,000", "80,000", "90,000")) +
theme(axis.text.x = element_text(angle = 90, hjust=1, vjust=0.5, size = rel(0.75))) +
labs(title="Home Mortgage Applications per County of NJ >> Years: 2018-2019-2020", x="Counties", y="Number of Home Mortgage Applications")
# visualize ethnicity
ggplot(data=fivaL) +
geom_bar(mapping=aes(x=et)) +
coord_cartesian(ylim=c(0,900000)) +
scale_y_continuous(breaks=c(100000, 200000, 300000, 400000, 500000, 600000, 700000, 800000, 900000),
labels=c("100,000", "200,000", "300,000", "400,000", "500,000", "600,000", "700,000", "800,000", "900,000")) +
labs(title="Ethnicity of Mortgage Applicants >> Period: 2018-2019-2020", x="", y="Number of Applications")
# visualize sex
ggplot(data=fivaL) +
geom_bar(mapping=aes(x=se)) +
coord_cartesian(ylim=c(0,900000)) +
scale_y_continuous(breaks=c(100000, 200000, 300000, 400000, 500000, 600000, 700000, 800000, 900000),
labels=c("100,000", "200,000", "300,000", "400,000", "500,000", "600,000", "700,000", "800,000", "900,000")) +
labs(title="Sex of Mortgage Applicants >> Period: 2018-2019-2020", x="", y="Number of Applications")
# action taken
ggplot(data=fivaL) +
geom_bar(mapping=aes(x=at)) +
scale_x_continuous(breaks=c(1, 2, 3, 4, 5, 6, 7, 8),
labels=c("Loan originated", "Application approved but not accepted", "Application denied", "Application withdrawn by applicant", "File closed for incompleteness", "Purchased loan", "Preapproval request denied", "Preapproval request approved but not accepted")) +
scale_y_continuous(breaks=c(100000, 200000, 300000, 400000, 500000, 600000, 700000, 800000, 900000),
labels=c("100,000", "200,000", "300,000", "400,000", "500,000", "600,000", "700,000", "800,000", "900,000")) +
theme(axis.text.x = element_text(angle = 90, hjust=1, vjust=0.5, size = rel(1.0))) +
labs(title="Action Taken by the Bank on Mortgage Application >> Period: 2018-2019-2020", x="", y="Number of Applications")
# loan purpose
fivaL$lp <- as.character(fivaL$lp) # convert 'lp' into a character variable
ggplot(data=fivaL) +
geom_bar(mapping=aes(x=lp)) +
scale_x_discrete(breaks=c(1, 2, 31, 32, 4, 5, NA),
labels=c("Home Purchase", "Home Improvement", "Refinancing", "Cash-out Refinancing", "Other Purpose", "Not Applicable", "NA")) +
coord_cartesian(ylim=c(0, 400000)) +
scale_y_continuous(breaks=c(50000, 100000, 150000, 200000, 250000, 300000, 350000, 400000),
labels=c("50,000", "100,000", "150,000", "200,000", "250,000", "300,000", "350,000", "400,000")) +
theme(axis.text.x = element_text(angle = 90, hjust=1, vjust=0.5, size = rel(1.0))) +
labs(title="Purpose of Loan Application >> Period: 2018-2019-2020", x="", y="Number of Applications")
# occupancy type
ggplot(data=fivaL) +
geom_bar(mapping=aes(x=ot)) +
scale_y_continuous(breaks=c(100000, 200000, 300000, 400000, 500000, 600000, 700000, 800000, 900000),
labels=c("100,000", "200,000", "300,000", "400,000", "500,000", "600,000", "700,000", "800,000", "900,000")) +
scale_x_continuous(breaks=c(1:3), labels=c("Principal Residence", "Second Residency", "Investment Property")) +
theme(axis.text.x = element_text(angle = 90, hjust=1, vjust=0.5, size = rel(1.0))) +
labs(title="Type of Mortgage Application >> Period: 2018-2019-2020", x="", y="Number of Applications")
# reason for denial
fivaL.denial <- filter(fivaL, dr %in% c(1:9)) # filter dataset for the first 9 values in dr variable only
ggplot(data=fivaL.denial) +
geom_bar(mapping=aes(x=dr)) +
scale_x_continuous(breaks=c(1:9), labels=c("Debt-to-Income Ratio", "Employment History", "Credit History", "Collateral", "Insufficient Cash (downpayment closing costs)", "Unverifiable Information", "Credit Application Incomplete", "Mortgage Insurance Denied", "Other")) +
scale_y_continuous(breaks=c(10000, 20000, 30000, 40000, 50000, 60000),
labels=c("10,000", "20,000", "30,000", "40,000", "50,000", "60,000")) +
theme(axis.text.x = element_text(angle = 90, hjust=1, vjust=0.5, size = rel(1.0))) +
labs(title="Reason for Denial on Mortgage Application >> Period: 2018-2019-2020", x="", y="Number of Denied Applications")
# visualize dinra
ggplot(data=fivaL) +
geom_bar(mapping=aes(x=factor(dinra, order=TRUE, levels=c("up_to_19%", "20_to_29%", "30_to_35%", "36%", "37%", "38%", "39%", "40%", "41%", "42%", "43%", "44%", "45%", "46%", "47%", "48%", "49%", "50_to_60%", "61%_and_above", "Exempt", "NA")))) +
coord_cartesian(ylim=c(0, 350000)) +
scale_y_continuous(breaks=c(50000, 100000, 150000, 200000, 250000, 300000, 350000),
labels=c("50,000", "100,000", "150,000", "200,000", "250,000", "300,000", "350,000")) +
theme(axis.text.x = element_text(angle = 90, hjust=1, vjust=0.5, size = rel(1.0))) +
labs(title="Debt-to-Income-Ratio of Home Mortgage Application >> Period: 2018-2019-2020", x="", y="Number of Applications")
























Figure 6. Distribution of values for categorical variables across 966,353 home mortgage applications (fivaL data frame).
My results shown on Figure 6 demonstrate that there was a sharp increase in home mortgage application for 2020 in relation to the previous two years. A total of 933 financial institutions processed 966,353 home mortgage applications, from which 621,767 applications (64.34%) came from the top 50 financial institutions (5.36%). Wells Fargo Bank was the institution that processed the most applications in New Jersey, followed by Rocket Mortgage LLC and Bank of America. The top 3 counties with more applicants were Ocean, Middlesex and Bergen; closely followed by Monmouth county. Non-latino applicants were about 8 times more than latino applicants; with white applicants being the major race, followed by Asian and African Americans, respectively. Male applicants exceeded female applicants. Principal residency was the main type of mortgage application whereas home purchase and refinancing were the main two purposes associated with mortgage applications. The two most frequent actions taken by the bank on the mortgage application were 'loan origination' and 'application denied'; with the principal reasons for denial ought to debt-to-income-ratio, credit history and collateral, respectively. The most frequent debt-to-income-ratio reported by applicants was from 36 to 49%.
The distribution of values for continuous variables is shown on Figure 7. It can be seen that the least skewed variable is interest_rate, with a relative plateau between 3.75 to 4.75%.
# VISUALIZE DISTRIBUTION OF VALUES WITHIN CONTINUOUS VARIABLES
describe(fivaL[, c(9, 10, 11, 13)])
# Loan Amount
ggplot(data=fivaL) +
geom_histogram(mapping=aes(x=la), binwidth=10000) +
coord_cartesian(xlim=c(0, 700000)) +
scale_x_continuous(breaks=c(100000, 200000, 300000, 400000, 500000, 600000, 700000), labels=c("$100,000", "$200,000", "300,000", "$400,000", "$500,000", "$600,000", "$700,000")) +
scale_y_continuous(breaks=c(10000, 20000, 30000, 40000, 50000),
labels=c("10,000", "20,000", "30,000", "40,000", "50,000")) +
labs(title="Loan Amount Requested in Application >> Period: 2018-2019-2020", x="", y="Number of Applications")
# property value
ggplot(data=fivaL) +
geom_histogram(mapping=aes(x=pv), binwidth=20000) +
scale_x_continuous(breaks=c(100000, 200000, 300000, 400000, 500000, 600000, 700000, 800000, 900000, 1000000), labels=c("$100,000", "$200,000", "$300,000", "$400,000", "$500,000", "$600,000", "$700,000", "$800,000", "$900,000", "$1,000,000")) +
coord_cartesian(xlim=c(0, 1000000)) +
scale_y_continuous(breaks=c(10000, 20000, 30000, 40000), labels=c("10,000", "20,000", "30,000", "40,000")) +
coord_cartesian(ylim=c(0, 40000)) +
labs(title="Property Value in Loan Application >> Period: 2018-2019-2020", x="", y="Number of Applications")
# interest rate
ggplot(data=fivaL) +
geom_histogram(mapping=aes(x=ir), binwidth=0.25) +
coord_cartesian(xlim=c(0,7)) +
scale_x_continuous(breaks=c(0:7), labels=c("0", "1%", "2%", "3%", "4%", "5%", "6%", "7%")) +
scale_y_continuous(breaks=c(10000, 20000, 30000, 40000, 50000, 60000), labels=c("10,000", "20,000", "30,000", "40,000", "50,000", "60,000")) +
coord_cartesian(ylim=c(0, 60000)) +
labs(title="Interest Rate on Loan Application >> Period: 2018-2019-2020", x="", y="Number of Applications")
# income
ggplot(data=fivaL) +
geom_histogram(mapping=aes(x=inc), binwidth = 10000) +
coord_cartesian(xlim=c(0,300000)) +
scale_x_continuous(breaks=c(50000, 100000, 150000, 200000, 250000, 300000), labels=c("$50K", "$100K", "$150K", "$200K", "$250k", "$300K")) +
scale_y_continuous(breaks=c(10000, 20000, 30000, 40000, 50000, 60000, 70000), labels=c("10,000", "20,000", "30,000", "40,000", "50,000", "60,000", "70,000")) +
coord_cartesian(ylim=c(0, 70000)) +
labs(title="Income on Home Mortgage Applications >> Period: 2018-2019-2020", x="", y="Number of Applications")








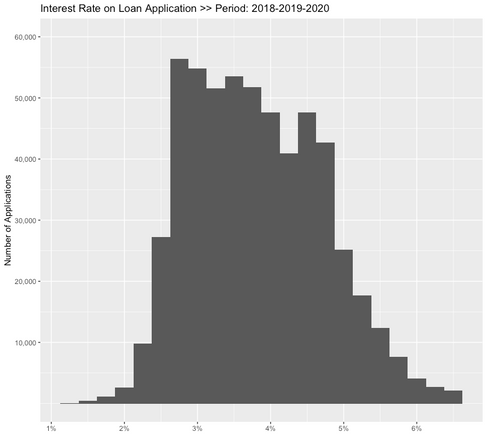
Figure 7. Distribution of values for continuous variables across 966,353 home mortgage applications (fivaL data frame).
Since I have inspected all single variables (one at a time) present in my data frame, I can now focus my attention in the visualization of the relationship between two or more variables in order to identify covariation. I can visualize the relationship between (a) categorical variables, (b) between categorical and continuous variables, and (c) between continuous variables.
I was intrigued by the distribution of values of the loan_purpose (lp) variable (Figure 6), and in particular with those home mortgage applications that had to do with refinancing. Thus, the first question I asked was: did the proportion of refinancing applications (relative to the total number of loan applications) changed in 2020 (the year of the covid-19 pandemic) in comparison to 2019 and 2018? As shown in Figure 8, the proportion of applications for refinancing did increase in 2020 compared to the previous two years, and the increase was evident across ethnic groups (latino and non-latino) and racial groups (Asian, African American, and white) as well. Unexpectedly (at least to me), the biggest increase in the proportion of refinancing applications in 2020 was observed for Asians.
library(MetBrewer)
str(fivaL)
fivaL$lp[fivaL$lp == "1"] <- "Home_Purchase"
fivaL$lp[fivaL$lp == "2"] <- "Home_Improvement"
fivaL$lp[fivaL$lp == "31"] <- "Refinancing"
fivaL$lp[fivaL$lp == "32"] <- "Cash_Out_refinancing"
fivaL$lp[fivaL$lp == "4"] <- "Other_Purpose"
fivaL$lp[fivaL$lp == "5"] <- "Not_Applicable"
ggplot(data=fivaL, aes(x=yr, fill=lp)) +
geom_bar(position="fill") +
scale_fill_manual(values=met.brewer('OKeeffe1', 6)) +
labs(title="Proportion of Home Mortgage Applications according to Loan Purpose (lp) per Year", x="", y="Proportion of Applications: 1.00 = 100%")
ggplot(data=fivaL, aes(x=yr, fill=lp)) +
geom_bar(position="fill") +
scale_fill_manual(values=met.brewer('OKeeffe1', 6)) +
facet_wrap(~et, nrow=1) +
labs(title="Proportion of Home Mortgage Applications according to Loan Purpose (lp) per Year", x="", y="Proportion of Applications: 1.00 = 100%")
# visualize refinancing per year per race (Asian, African American, and White)
fivaL.ra <- filter(fivaL, ra %in% c("Asian", "Black or African American", "White")) # filter fivaL dataframe based on 3 mayor races
ggplot(data=fivaL.ra, aes(x=yr, fill=lp)) +
geom_bar(position="fill") +
scale_fill_manual(values=met.brewer('OKeeffe1', 6)) +
facet_wrap(~ra, nrow=1) +
labs(title="Proportion of Home Mortgage Applications according to Loan Purpose (lp) per Year", x="", y="Proportion of Applications: 1.00 = 100%")






Figure 8. Visualization of the proportion of home loan applications that were destined for refinancing relative to all other loan applications for the years 2018, 2019 and 2020; and across ethnic (latino vs non-latino) and racial (Asian, African American, and white) group of applicants.
A HOME REFINANCING STORY FOR ASIAN LOAN APPLICANTS
What could possibly be the cause behind the pronounced increase in the proportion of refinancing loan applications among Asians relative to African Americans and white applicants? Could it be a mayor decrease in income for Asians in 2020 compared to African Americans and whites? Could it be Asians had borrowed bigger loan amounts in 2018 and 2019 compared to African Americans and whites and thus needed to apply for refinancing in 2020? Or could it be associated with changes in interest rates in 2020 compared to the previous two years? The visualization shown on Figure 9 suggests that increased loan amounts and reduced interest rates for Asians might have played a role in their increased proportion of refinancing loans observed in 2020. To test this, I re-focused my analysis on refinancing applications ONLY and observed the distribution of values for income, loan amount and interest rate across years and race (Figure 10). I found out the the results shown on Figure 9 held true when refinancing loan applications only were analyzed.
# visualize income for 3 mayor races across years
ggplot(data=fivaL.ra, aes(x=factor(yr), y=inc)) +
geom_boxplot() +
facet_wrap(~ra, nrow=1) +
scale_y_continuous(breaks=c(50000, 75000, 100000, 125000, 150000, 175000, 200000, 225000, 250000, 275000, 300000), labels=c("$50K", "$75K", "$100K", "$125K", "$150K", "$175K", "$200K", "$225K", "$250K", "$275K", "$300K")) +
labs(title="Income of Home Loan Applicants per Year", x="", y="Income in Thousand of Dollars")
# visualize loan amount for 3 mayor races across years
ggplot(data=fivaL.ra, aes(x=factor(yr), y=la)) +
geom_boxplot() +
facet_wrap(~ra, nrow=1) +
scale_y_continuous(breaks=c(100000, 150000, 200000, 250000, 300000, 350000, 400000, 450000, 500000, 550000, 600000, 650000, 700000, 750000), labels=c("$100K", "$150K", "$200K", "$250K", "$300K", "$350K", "$400K", "$450K", "$500K", "$550K", "$600K", "$650K", "$700K", "$750K")) +
labs(title="Loan Amount of Applicants per Year", x="", y="Loan Amount in Thousand of Dollars")
# visualize interest rate for 3 mayor races across years
ggplot(data=fivaL.ra, aes(x=factor(yr), y=ir)) +
geom_boxplot() +
facet_wrap(~ra, nrow=1) +
scale_y_continuous(breaks=c(0:7), labels=c("0", "1%", "2%", "3%", "4%", "5%", "6%", "7%")) +
labs(title="Interest Rate of Applicants per Year", x="", y="Interest Rate")






Figure 9. Visualization of the distribution of values for income, loan amount and interest rate across years and racial group of applicants.
# re-focus analysis ONLY on loan applications whose purpose was refinancing
fivaL.ra.refinancing <- filter(fivaL.ra, lp == "Refinancing") # filter fivaL.ra dataframe based on refinancing
str(fivaL.ra.refinancing) # 264,791 observations / applications
# visualize income for refinanced loan applications across year and race
ggplot(data=fivaL.ra.refinancing, aes(x=factor(yr), y=inc)) +
geom_boxplot() +
facet_wrap(~ra, nrow=1) +
scale_y_continuous(breaks=c(50000, 75000, 100000, 125000, 150000, 175000, 200000, 225000, 250000, 275000, 300000), labels=c("$50K", "$75K", "$100K", "$125K", "$150K", "$175K", "$200K", "$225K", "$250K", "$275K", "$300K")) +
labs(title="Income of Refinancing Loan Applications per Year", x="", y="Income in Thousand of Dollars")
# visualize loan amount for refinanced loan applications across year and race
ggplot(data=fivaL.ra.refinancing, aes(x=factor(yr), y=la)) +
geom_boxplot() +
facet_wrap(~ra, nrow=1) +
scale_y_continuous(breaks=c(100000, 150000, 200000, 250000, 300000, 350000, 400000, 450000, 500000, 550000, 600000, 650000, 700000, 750000), labels=c("$100K", "$150K", "$200K", "$250K", "$300K", "$350K", "$400K", "$450K", "$500K", "$550K", "$600K", "$650K", "$700K", "$750K")) +
labs(title="Loan Amount of Refinancing Applications per Year", x="", y="Loan Amount in Thousand of Dollars")
# visualize interest rate for refinanced loan applications across year and race
ggplot(data=fivaL.ra.refinancing, aes(x=factor(yr), y=ir)) +
geom_boxplot() +
facet_wrap(~ra, nrow=1) +
scale_y_continuous(breaks=c(0:7), labels=c("0", "1%", "2%", "3%", "4%", "5%", "6%", "7%")) +
labs(title="Interest Rate of Refinancing Applications per Year", x="", y="Interest Rate")






Figure 10. Visualization of the distribution of values for income, loan amount and interest rate for loan applications of purpose refinancing ONLY across years and racial group of applicants.
Finally, I was curious to know which of the top 50 financial institutions gave the lowest interest rates for refinancing loan applications in 2020 when Asians were the applicants (Figure 11A). Around 16 financial institutions displayed median interest rates close to 2.71%. A total of 28,456 applications were evenly processed across the top 50 financial institutions in New Jersey (Figure 11B).
# perform EDA on top50 financial institutions data frame
str(data.top50.fi)
# rename loan purpose variable's values
data.top50.fi$lp[data.top50.fi$lp == "1"] <- "Home_Purchase"
data.top50.fi$lp[data.top50.fi$lp == "2"] <- "Home_Improvement"
data.top50.fi$lp[data.top50.fi$lp == "31"] <- "Refinancing"
data.top50.fi$lp[data.top50.fi$lp == "32"] <- "Cash_Out_refinancing"
data.top50.fi$lp[data.top50.fi$lp == "4"] <- "Other_Purpose"
data.top50.fi$lp[data.top50.fi$lp == "5"] <- "Not_Applicable"
# assign names to financial insitutions' lei
data.top50.fi$fi[data.top50.fi$fi %in% fi.ID] <- fi.name
data.top50.fi.asian <- filter(data.top50.fi, ra == "Asian") # select asian applicants
data.top50.fi.asian.refinancing <- filter(data.top50.fi.asian, lp == "Refinancing") # select refinancing loans
str(data.top50.fi.asian.refinancing) # refinancing applications from asians >> 28,456 applications
# visualize interest rates per financial insitution per year for asian refinancing loan applicants
# set vertical red-dashed line at interest rate of 2.71%
ggplot(data=data.top50.fi.asian.refinancing, aes(x=fi, y=ir)) +
geom_boxplot(notch=TRUE) +
facet_wrap(~yr, nrow=1) +
scale_y_continuous(breaks=c(0:7), labels=c("0", "1%", "2%", "3%", "4%", "5%", "6%", "7%")) +
coord_flip() +
labs(title="Interest Rate per Financial Insitution (top 50) for Asian Applicants (Refinancing Loans)", x="", y="Interest Rate") +
geom_hline(aes(yintercept = 2.71), linetype = "dashed", size = 1, color="red")

Figure 11A. Distribution of values for interest rates on refinancing loans from asian applicants for the top 50 financial institutions in New Jersey. The red-dashed line signal and interest rate of 2.71%.

Figure 11B. Number of applications from Asians on refinancing loans across the top 50 financial institutions in New Jersey for the year 2020.
A LATINO STORY HIDDEN IN HOME LOAN APPLICATIONS
The number of home loans from latinos in the three year period of study totaled 111,558 applications. Although the number of latino applications increased from 2018 to 2020, the proportion relative to all the applications decreased from 12.6% in 2018 to 11.5% in 2020 (Figure 12). The greatest proportion of latino applicants identified as 'white' and were males (Figure 13). Although the greatest number of latino applications came from Bergen County, the biggest proportion of home loan applicants from latinos relative to all applications was in Passaic County (Figure 14).
# how many mortgage applications from latinos?
latinos <- filter(fivaL, et == "Latino")
str(latinos) # 111,558 observations
# visualize number of latino applications per year
ggplot(data=latinos) +
geom_bar(mapping=aes(x=factor(yr))) +
scale_y_continuous(breaks=c(10000, 20000, 30000, 40000), labels=c("10,000", "20,000", "30,000", "40,000")) +
labs(title="Home Mortgage Applications from Latinos", x="", y="Number of Applications")
# visualize proportion of latinos relative to total number of applications per year
dt <- fivaL %>%
dplyr::group_by(yr, et) %>%
dplyr::tally() %>%
dplyr::mutate(percent=n/sum(n))
pl <- ggplot(data = dt, aes(x=yr, y = n, fill = et)) +
scale_fill_manual(values=met.brewer("Morgenstern", 2)) +
scale_y_continuous(breaks=c(100000, 200000, 300000, 400000), labels=c("100,000", "200,000", "300,000", "400,000")) +
labs(title="Proportion of Latino Applications", x="", y="Number of Applications")
pl <- pl + geom_bar(stat="identity")
pl <- pl + geom_text(aes(label=paste0(sprintf("%1.1f", percent*100),"%")),
position=position_stack(vjust=0.5), colour="white", size = 3)
pl <- pl + theme(axis.text.x = element_text(angle = 90,hjust =0 ))
pl
# vsiualize proportion of latinos based on race relative to total number of applications per year
latinos.ra <- filter(latinos, ra %in% c("Asian", "Black or African American", "White")) # filter latinos dataframe based on 3 mayor races
la.ra <- latinos.ra %>%
dplyr::group_by(yr, ra) %>%
dplyr::tally() %>%
dplyr::mutate(percent=n/sum(n))
pl.2 <- ggplot(data = la.ra, aes(x=yr, y = n, fill = ra)) +
scale_fill_manual(values=met.brewer("Morgenstern", 3)) +
scale_y_continuous(breaks=c(10000, 20000, 30000, 40000), labels=c("10,000", "20,000", "30,000", "40,000")) +
labs(title="Proportion of Race Among Latino Applicants", x="", y="Number of Applications")
pl.2 <- pl.2 + geom_bar(stat="identity")
pl.2 <- pl.2 + geom_text(aes(label=paste0(sprintf("%1.1f", percent*100),"%")),
position=position_stack(vjust=0.5), colour="white", size = 3)
pl.2 <- pl.2 + theme(axis.text.x = element_text(angle = 90,hjust =0 ))
pl.2
# visualize the sex of latino applicants per year
la.se <- latinos %>%
dplyr::group_by(yr, se) %>%
dplyr::tally() %>%
dplyr::mutate(percent=n/sum(n))
pl.4 <- ggplot(data = la.se, aes(x=yr, y = n, fill = se)) +
scale_fill_manual(values=met.brewer("Morgenstern", 4)) +
scale_y_continuous(breaks=c(10000, 20000, 30000, 40000), labels=c("10,000", "20,000", "30,000", "40,000")) +
labs(title="Proportion of Sex Among Latino Applicants", x="", y="Number of Applications")
pl.4 <- pl.4 + geom_bar(stat="identity")
pl.4 <- pl.4 + geom_text(aes(label=paste0(sprintf("%1.1f", percent*100),"%")),
position=position_stack(vjust=0.5), colour="white", size = 3)
pl.4 <- pl.4 + theme(axis.text.x = element_text(angle = 90, hjust =0 ))
pl.4
# visualize proportion of latino applications per county
countyCodesNJ <- filter(fivaL, cc %in% county.codes.names)
countyCodes <- countyCodesNJ %>%
dplyr::group_by(cc, et) %>%
dplyr::tally() %>%
dplyr::mutate(percent=n/sum(n))
pl.5 <- ggplot(data = countyCodes, aes(x=cc, y = n, fill = et)) +
scale_fill_manual(values=met.brewer("Morgenstern", 2)) +
scale_y_continuous(breaks=c(10000, 20000, 30000, 40000, 50000, 60000, 70000, 80000, 90000), labels=c("10,000", "20,000", "30,000", "40,000", "50,000", "60,000", "70,000", "80,000", "90,000")) +
labs(title="Proportion of Latino Applicants per County", x="", y="Number of Applications")
pl.5 <- pl.5 + geom_bar(stat="identity")
pl.5 <- pl.5 + geom_text(aes(label=paste0(sprintf("%1.1f", percent*100),"%")),
position=position_stack(vjust=0.5), colour="white", size = 2)
pl.5 <- pl.5 + theme(axis.text.x = element_text(angle = 90, hjust =0 ))
pl.5
# visualize number of latino applications per county
latinos.per.county <- filter(countyCodesNJ, et == "Latino")
ggplot(data=latinos.per.county) +
geom_bar(aes(x=cc)) +
scale_y_continuous(breaks=c(5000, 10000, 15000), labels=c("5,000", "10,000", "15,000")) +
theme(axis.text.x = element_text(angle = 90, hjust = 0)) +
labs(title="Latino Home Mortgage Applications per County", x="", y="Number of Applications")



Figure 12. Home loan applications from latinos per year. Total count of applications (left chart) and proportion relative to all applications (right chart).




Figure 13. Latino home loan applicants are mainly white and males.




Figure 14. Home loan applications from latinos per county in New Jersey. Total number of applications are shown on the the left chart, and the proportion of latino applications relative to all applications per county are shown on the right chart.
It is interesting to note that while the income reported from latinos was lower in comparison to not.hispanic applicants, the loan amount they requested in their loan applications was comparable to that from not.hispanics. Furthermore, the property value aspired to or bought by latinos was cheaper in relation to that from not.hispanics (Figure 15). This findings are in accordance to what I've previously reported on the HMDA dataset (see refs).
# visualize income for latinos per year
ggplot(data=fivaL) +
geom_boxplot(mapping=aes(x=et, y=inc)) +
facet_wrap(~yr, nrow=1) +
scale_y_continuous(breaks=c(50000, 75000, 100000, 125000, 150000, 175000, 200000, 225000, 250000, 275000, 300000), labels=c("$50K", "$75K", "$100K", "$125K", "$150K", "$175K", "$200K", "$225K", "$250K", "$275K", "$300K")) +
theme(axis.text.x = element_text(angle = 90, hjust =0.5 )) +
labs(title="Income reported on Home Loan Applications", x="", y="Income in Thousand of Dollars")
# visualize loan_amount for latinos per year
ggplot(data=fivaL) +
geom_boxplot(mapping=aes(x=et, y=la), notch = TRUE) +
facet_wrap(~yr, nrow=1) +
scale_y_continuous(breaks=c(0, 50000, 100000, 150000, 200000, 250000, 300000, 350000, 400000, 450000, 500000, 550000, 600000, 650000, 700000), labels=c("$0K", "$50K", "$100K", "$150K", "$200K", "$250K", "$300K", "$350K", "$400K", "$450K", "$500K", "$550K", "$600K", "$650K", "$700K")) +
theme(axis.text.x = element_text(angle = 90, hjust =0.5 )) +
labs(title="Loan Amount reported by Latinos on Home Mortgage Applications", x="", y="Loan in Thousand of Dollars")
# visualize property value for latinos per year
ggplot(data=fivaL) +
geom_boxplot(mapping=aes(x=et, y=pv)) +
facet_wrap(~yr, nrow=1) +
scale_y_continuous(breaks=c(0, 50000, 100000, 150000, 200000, 250000, 300000, 350000, 400000, 450000, 500000, 550000, 600000, 650000, 700000, 750000, 800000, 850000, 900000, 1000000), labels=c("$0K", "$50K", "$100K", "$150K", "$200K", "$250K", "$300K", "$350K", "$400K", "$450K", "$500K", "$550K", "$600K", "$650K", "$700K", "$750K", "$800K", "$850K", "$900K", "$950K, $1000K")) +
theme(axis.text.x = element_text(angle = 90, hjust =0.5 )) +
labs(title="Property Value reported by Latinos on Home Mortgage Applications", x="", y="Value in Thousand of Dollars")





Figure 15. Box plots displaying the distribution of values for the income, loan_amount, and property_value variables depending on the ethnicity of the home loan applicant.
When I looked to loans originated, the median for the interest_rate variable was higher for the latino applicant compared to the not.hispanic (Figure 16). This may have to do (possibly?) with the fact that latino applicants reported a median income lower than not.hispanic but the median for loan amounts requested was comparable to not.hispanics (Figure 15). When the top 50 financial institutions of New Jersey are taken into account, interest rates for latinos compared to not.hispanics differed per institutions and per year (Figure 17A); however a clear trend of higher interest rates for latino applicants is evident when the three years of study are combined for each of the top 50 financial institutions (Figure 17B).
# visualize interest for latinos per year
ggplot(data=fivaL) +
geom_boxplot(mapping=aes(x=et, y=ir), notch=TRUE) +
facet_wrap(~yr, nrow=1) +
scale_y_continuous(breaks=c(0:7), labels=c("0", "1%", "2%", "3%", "4%", "5%", "6%", "7%")) +
theme(axis.text.x = element_text(angle = 90, hjust =0.5 )) +
labs(title="Interest Rate on Mortgage Applications by Latinos", x="", y="Interest Rate")
Figure 16. Box plot displaying the variation in values for the interest_rate variable based on the ethnicity of the home loan applicant.
# now plot interest_rate per bank, per ethnicity and per year
ggplot(data=data.top50.fi, aes(x=ir, y=reorder(fi, ir))) +
geom_boxplot(aes(color=et), notch=TRUE) +
facet_wrap(~yr) +
scale_x_continuous(breaks=c(0:7), labels=c("0", "1%", "2%", "3%", "4%", "5%", "6%", "7%")) +
labs(title="Interest Rate on Mortgage Applications by Financial Institution", x="Interest Rate", y="Top 50 Financial Institutions in New Jersey")
ggplot(data=data.top50.fi, aes(x=ir, y=reorder(fi, ir))) +
geom_boxplot(aes(fill=et), notch=TRUE) +
scale_fill_manual(values=met.brewer("Cassatt1", 2)) +
scale_x_continuous(breaks=c(0:7), labels=c("0", "1%", "2%", "3%", "4%", "5%", "6%", "7%")) +
labs(title="Interest Rate (2018-2019-2020 average) on Mortgage Applications by Financial Institution", x="Interest Rate", y="Top 50 Financial Institutions in New Jersey")
Figure 17A. Box plots displaying variation in interest rates for the top 50 financial institutions in New Jersey based on the ethnicity of the home loan applicant.

Figure 17B. Box plots displaying variation in interest rates for the top 50 financial institutions in New Jersey (three years combined) based on the ethnicity of the home loan applicant.
I then proceeded to analyze home loan applications that were denied. After loan originations, denied applications were the most common actions taken by the banks (Figure 18). When investigating the reason by which a home loan application was denied, it came evident that debt-to-income ratio, credit history, and collateral were the three main factors for both latino and not.hispanic applicants (Figure 19). Since the HMDA datasets did not included credit scores and/or collateral information, I focused on analyzing debt-to-income ratio for all home loan applications (Figure 20A) and comparing it for denied-only applications (Figure 20B). The first thing I noticed was that for latino applicants in 2018 and 2019, the number of home loan applications displaying debt-to-income ratios 50% and above were the most frequent. This did not happen for not.hispanic applicants during the same period in which applications displaying debt-to-income ratios between 20 to 35% were the most frequent (Figure 20A). For denied applications only, the debt-to-income ratios most frequents were 50% and above for both latinos and not.hispanic applicants (Figure 20B).
# rename action taken from numeric to character
# visualize action taken by the bank on latinos
fivaL$at[fivaL$at == 1] <- "Loan Originated"
fivaL$at[fivaL$at == 2] <- "Application approved but not accepted"
fivaL$at[fivaL$at == 3] <- "Application denied"
fivaL$at[fivaL$at == 4] <- "Application withdrawn by applicant"
fivaL$at[fivaL$at == 5] <- "File closed for incompleteness"
fivaL$at[fivaL$at == 6] <- "Purchased loan"
fivaL$at[fivaL$at == 7] <- "Preapproval request denied"
fivaL$at[fivaL$at == 8] <- "Preapproval request approved but not accepted"
ggplot(data=fivaL) +
geom_bar(mapping=aes(x=at)) +
facet_grid(et~yr, scale="free_y") +
theme(axis.text.x = element_text(angle = 90, hjust=1, vjust=0.5, size = rel(1.0))) +
labs(title="Action Taken by the Bank on Mortgage Application by Latinos", x="", y="Number of Applications")
Figure 18. Home loan applications visually organized by action taken by the bank on the processed loan.
# {1} visualize denial reason for latinos
denial.fivaL <- filter(fivaL, dr %in% c(1:9)) #filter dataset for the first 9 values only
ggplot(data=denial.fivaL) +
geom_bar(mapping=aes(x=dr)) +
facet_grid(et~yr, scales="free_y") +
scale_x_continuous(breaks=c(1:9), labels=c("Debt-to-Income Ratio", "Employment History", "Credit History", "Collateral", "Insufficient Cash (downpayment closing costs)", "Unverifiable Information", "Credit Application Incomplete", "Mortgage Insurance Denied", "Other")) +
theme(axis.text.x = element_text(angle = 90, hjust=1, vjust=0.5, size = rel(1.0))) +
labs(title="Reason for Denied Mortgage Applications on Latinos", x="", y="Number of Denied Applications")
Figure 19. Denied home loan applications were visualized based on the reason for denial given by the financial institution.
# visualize debt-to-income-ratio by latinos per year
ggplot(data=fivaL) +
geom_bar(mapping=aes(x=factor(dinra, order=TRUE, levels=c("up_to_19%", "20_to_29%", "30_to_35%", "36%", "37%", "38%", "39%", "40%", "41%", "42%", "43%", "44%", "45%", "46%", "47%", "48%", "49%", "50_to_60%", "61%_and_above", "Exempt", "NA")))) +
facet_grid(et~yr, scales="free_y") +
theme(axis.text.x = element_text(angle = 90, hjust =0.5 )) +
labs(title="Debt-to-Income-Ratio on Latino Home Mortgage Applications", x="", y="Number of Applications")
Figure 20A. All home loan applications were plotted based on debt-to-income ratios for latino and not.hispanic applicants.
# {1} visualize denial reason for latinos
denial.fivaL <- filter(fivaL, dr %in% c(1:9)) #filter dataset for the first 9 values only
ggplot(data=denial.fivaL) +
geom_bar(mapping=aes(x=dr)) +
facet_grid(et~yr, scales="free_y") +
scale_x_continuous(breaks=c(1:9), labels=c("Debt-to-Income Ratio", "Employment History", "Credit History", "Collateral", "Insufficient Cash (downpayment closing costs)", "Unverifiable Information", "Credit Application Incomplete", "Mortgage Insurance Denied", "Other")) +
theme(axis.text.x = element_text(angle = 90, hjust=1, vjust=0.5, size = rel(1.0))) +
labs(title="Reason for Denied Mortgage Applications on Latinos", x="", y="Number of Denied Applications")
Figure 20B.Denied home loan applications were plotted based on debt-to-income ratios for latino and not.hispanic applicants.
I subsequently focused on denied applications as a proportion of all applications for latinos and not.hispanic applicants, respectively. In doing so I learned a hard truth, that latinos as group displayed a bigger proportion of denied applications relative to not.hispanics (Figure 21). I then tried to understand denial patterns towards latinos for the top 50 financial institutions in New Jersey (Figure 22) and uncovered that with the exception of TD Bank in 2020, the proportion of denied applications was always higher for latino applicants. When the distribution of percentages of denial per bank was visualized for latinos in relation to not.hispanics the difference between these groups of applicants was very clear (Figure 23).
denied.applications <- filter(fivaL, at == "Application denied")
denied.applications <- filter(fivaL, dr %in% c(1:9)) # filter dataset for the first 9 reasons only
str(denied.applications) # 155,571 observations
# because fivaL has 966,356 applications, then
denied.applications.latinos <- filter(denied.applications, et == "Latino")
str(denied.applications.latinos) # 25,383 observations
denied.applications.NOT.hispanics <- filter(denied.applications, et == "Not.Hispanic")
str(denied.applications.NOT.hispanics) # 130,188 observations
fivaL.latinos <- filter(fivaL, et == "Latino")
str(fivaL.latinos) # 111,558 applications
fivaL.NOT.hispanics <- filter(fivaL, et == "Not.Hispanic")
str(fivaL.NOT.hispanics) # 800,450 applications
# (denied.applications.latinos x 100) / total.applications.latinos > (25,383*100)/111,558 = 22.7%
# (denied.applications.NOT.hispanics x 100) / total.applications.NOT.hispanics > (130,188*100)/800,450 = 16.3%
# create tibble 1
denied.by.ethnicity <- denied.applications %>%
group_by(yr, et) %>%
summarize(n1 = n())
denied.by.ethnicity # total number of applications denied summarized by year and ethnicity
# create tibble 2
total.applications.by.ethnicity <- fivaL %>%
group_by(yr, et) %>%
summarize(n2 = n())
total.applications.by.ethnicity <- na.omit(total.applications.by.ethnicity) # total number of applications summarized by year and ethnicity
# combine columns from tibble 1 and tibble 2 into a new tibble 3
# create tibble 3
percentage.Denial <- tibble(total.applications.by.ethnicity$yr, total.applications.by.ethnicity$et, total.applications.by.ethnicity$n2, denied.by.ethnicity$n1)
percentage.Denial
# add percentage column
percentage.Denial <- mutate(percentage.Denial,
pct.Denied = (denied.by.ethnicity$n1*100)/total.applications.by.ethnicity$n2) # I DID IT!!!
# visualize percentage of denial applications relative to total applications per year per ethnicity
ggplot(data=percentage.Denial, aes(x=`total.applications.by.ethnicity$et`, y=pct.Denied, fill=`total.applications.by.ethnicity$et`)) +
scale_fill_manual(values=met.brewer("Cassatt1", 2)) +
geom_col() +
facet_wrap(~`total.applications.by.ethnicity$yr`, nrow=1) +
geom_text(aes(label=round(pct.Denied, digits=2), vjust=1.5)) +
scale_y_continuous(breaks=c(5, 10, 15, 20, 25), labels=c("5%", "10%", "15%", "20%", "25%")) +
theme(legend.position = "none") +
labs(title="Percentage of Denied Applications relative to all applications", x="", y="Percentage of Denied Applications") 
Figure 21. Plot displaying the proportion of denied applications (as percentage) relative to all applications per ethnic group and per year. Numbers within each bar represent the exact percentage of denied applications.
# HOW ABOUT DENIAL % BY BANK?
View(data.top50.fi)
# get ALL applications per bank, per ethnicity and per year (A)
applications.per.bank <- data.top50.fi %>%
group_by(fi, et, yr) %>%
summarize(c1 = n())
View(applications.per.bank)
# select denied applications
denied.applications.per.bank <- filter(data.top50.fi, at == 3)
View(denied.applications.per.bank)
# get DENIED applications per bank, per ethnicity and per year (B)
denied.per.bank <- denied.applications.per.bank %>%
group_by(fi, et, yr) %>%
summarize(c2 = n())
View(denied.per.bank)
# construct new data frame combining columns from C1 and C2
# get columns
Financial_Institution <- applications.per.bank$fi
Ethnicity <- applications.per.bank$et
Year <- applications.per.bank$yr
C1 <- applications.per.bank$c1
C2 <- denied.per.bank$c2
#create data frame
pct.denied.bank.year <- data.frame(Financial_Institution, Ethnicity, Year, C1, C2)
View(pct.denied.bank.year)
# add new column with pct of denial
mutate(pct.denied.bank.year, pct.Denied = (C2*100)/C1) # I DID IT!!!
pct.denied.bank.year <- mutate(pct.denied.bank.year, pct.Denied = (C2*100)/C1)
View(pct.denied.bank.year)
# plot this GREATNESS!
ggplot(data=pct.denied.bank.year, aes(x=pct.Denied, y=reorder(Financial_Institution, pct.Denied))) +
geom_point(aes(color=Ethnicity), size=3) +
facet_wrap(~Year) +
scale_x_continuous(breaks=c(5, 10, 15, 20, 25, 30, 35)) +
theme_bw() +
theme(
panel.grid.major.x = element_blank(),
panel.grid.minor.x = element_blank(),
panel.grid.major.y = element_line(color="grey80", linetype="dashed")
) +
labs(title="Percentage of Denied Home Mortgage Applications per Financial Institution", x="Percentage of Denied Applications", y="")
summary(pct.denied.bank.year$pct.Denied)
Figure 22. Plot visualizing the proportion (as percentage) of denied home loan applications relative to all processed applications per financial institution for latino (red) and not.hispanic applicants (green). Top 50 financial institutions in New Jersey are shown.
# write function to get stats and plug them as text into my boxplot
get_box_stats <- function(y, upper_limit = max(pct.denied.bank.year$pct.Denied) * 1.15) {
return(data.frame(
y = 0.95 * upper_limit,
label = paste(
#"Count =", length(y), "\n",
"Mean =", round(mean(y), 2), "\n",
"Median =", round(median(y), 2), "\n"
)
))
}
# plot distribution of percentage of denied applications for the top 50 banks
ggplot(data=pct.denied.bank.year, aes(x=Ethnicity, y=pct.Denied, fill=Ethnicity)) +
scale_fill_manual(values=met.brewer("Cassatt1", 2)) +
geom_boxplot() +
stat_summary(fun.data = get_box_stats, geom = "text", hjust = 0.5, vjust = 0.9, size=2.8) +
scale_y_continuous(breaks=c(5, 10, 15, 20, 25, 30, 35)) +
facet_wrap(~Year) +
labs(title="Distribution of Percentage of Denied Applications: Top 50 Financial Institutions in NJ", x="", y="% of Denied Applications") +
theme(legend.position="none")
Figure 23. Box plot visualizing the distribution of percentages of denial for the top 50 financial institutions based on the ethnicity of the applicant (latino in green and not.hispanic in red). This figure is highly related to Figure 22.
And how about long originations? Are latinos displaying an opposite pattern to the one presented in relation to denied applications? I found the proportion of loan originations for the top 50 financial institutions was lower for latino applicants compared to not.hispanics as shown on Figure 24.
# HOW ABOUT % LOAN ORIGINATIONS BY BANK?
View(data.top50.fi)
# get ALL applications per bank, per ethnicity and per year (c1)
applications.per.bank <- data.top50.fi %>%
group_by(fi, et, yr) %>%
summarize(c1 = n())
View(applications.per.bank)
# select ORIGINATED applications
ORIGINATED.applications.per.bank <- filter(data.top50.fi, at == 1)
View(ORIGINATED.applications.per.bank)
# get ORIGINATED applications per bank, per ethnicity and per year (c3)
ORIGINATED.per.bank <- ORIGINATED.applications.per.bank %>%
group_by(fi, et, yr) %>%
summarize(c3 = n())
View(ORIGINATED.per.bank)
# construct new data frame combining columns from c1 and c3
# get columns
Financial_Institution <- applications.per.bank$fi
Ethnicity <- applications.per.bank$et
Year <- applications.per.bank$yr
C1 <- applications.per.bank$c1
C3 <- ORIGINATED.per.bank$c3
#create data frame
pct.ORIGINATED.bank.year <- data.frame(Financial_Institution, Ethnicity, Year, C1, C3)
View(pct.ORIGINATED.bank.year)
# add new column with pct of ORIGINATIONS
mutate(pct.ORIGINATED.bank.year, pct.ORIGINATED = (C3*100)/C1) # I DID IT!!!
pct.ORIGINATED.bank.year <- mutate(pct.ORIGINATED.bank.year, pct.ORIGINATED = (C3*100)/C1) # SAVE NEW COLUMN (pct.ORIGINATED) back into data frame pct.ORIGINATED.bank.year
View(pct.ORIGINATED.bank.year)
# plot this GREATNESS!
ggplot(data=pct.ORIGINATED.bank.year, aes(x=pct.ORIGINATED, y=reorder(Financial_Institution, pct.ORIGINATED))) +
geom_point(aes(color=Ethnicity), size=3) +
scale_color_manual(values=met.brewer("Cassatt1", 2)) +
facet_wrap(~Year) +
coord_cartesian(xlim=c(30,65)) +
scale_x_continuous(breaks=c(30, 35, 40, 45, 50, 55, 60, 65)) +
theme_bw() +
theme(
panel.grid.major.x = element_blank(),
panel.grid.minor.x = element_blank(),
panel.grid.major.y = element_line(color="grey80", linetype="dashed")
) +
geom_text(aes(label=round(pct.ORIGINATED, digits = 2), hjust=1.3, color=Ethnicity), size=2.5) +
labs(title="Percentage of 'Loan_Originated' per Financial Institution", x="% Loan Originations", y="Top 50 Financial Institutions in New Jersey")
# dedicated function to plug into boxplot with median data
get_box_statsA <- function(y, upper_limit = max(pct.ORIGINATED.bank.year$pct.ORIGINATED) * 1.15) {
return(data.frame(
y = 0.95 * upper_limit,
label = paste(
#"Count =", length(y), "\n",
"Mean =", round(mean(y), 2), "\n",
"Median =", round(median(y), 2), "\n"
)
))
}
# plot distribution of percentage of ORIGINATED applications for the top 50 banks
ggplot(data=pct.ORIGINATED.bank.year, aes(x=Ethnicity, y=pct.ORIGINATED, fill=Ethnicity)) +
scale_fill_manual(values=met.brewer("Cassatt1", 2)) +
geom_boxplot() +
stat_summary(fun.data = get_box_statsA, geom = "text", hjust = 0.5, vjust = 0.9, size=2.8) +
coord_cartesian(ylim=c(30,65)) +
scale_y_continuous(breaks=c(30, 35, 40, 45, 50, 55, 60, 65)) +
facet_wrap(~Year) +
labs(title="Distribution of Percentage of Originated Loan Applications: Top 50 Financial Institutions in NJ", x="", y="% of Loan Originated Applications") +
theme(legend.position="none")



Figure 24. Plot displaying the proportion of loan originations (as percentage) relative to all home loan applications processed by each of the top 50 financial institutions in New Jersey for latino and not.hispanic applicants (left chart); and plot displaying the distribution of percentage values for loan originations processed by the top 50 financial institutions per ethnic group (right chart).
Overall, my results show that latinos are disfavored when it come to obtaining home loans in New Jersey.
References
Wickham, H and Grolemund, G (2017). R for data science: import, tidy, transform, visualize, and model data. Published by O'Reilly Media Inc., Sebastopol, California.
Kabacoff, RI (2015). R in Action: data analysis and graphics in R. Published by Manning, Shelter Island, New York.
Calvino (2021). Principal Component Analysis (PCA) in R. https://www.martincalvino.co/post/principal-component-analysis-pca-in-r


Comments